
#
Who verifies the verifier? — Building verifiable trust into confidential containers

#
Proving trust in confidential containers
Confidential computing starts with an uncomfortable observation: using someone else's infrastructure means trusting someone else's administrators. Traditionally that trust comes from contracts, audits, certifications, and operational controls — administrative assurances, not technical assurances.
In our architecture overview, Confidential Computing for Privacy-Preserving AI, we described the broader trust architecture behind the platform. This post focuses on a narrower part of it.
We've been following Confidential Containers technologies closely; as these technologies matured considerably over the past few years, we started exploring how the same principles could be applied to the workloads on our OpenShift cluster. Applying these technologies to the AI products we offer became a priority in particular. We carried out our testing through a collaboration with IBM Research that began last year and is still ongoing. And as the work evolved, the question we were asking came into sharper focus: can a workload running on an OpenShift cluster cryptographically prove what it is — with hardware-signed evidence, and without leaving a back door for administrators — before it gets access to sensitive resources? And can those decisions be enforced through attestation and policy rather than administrative privilege, keeping secrets protected inside the workloads themselves?
This post is about that question — about how we carried confidential computing, a sensitive topic for us since the company's earliest years, beyond VMs and into containers with Kata.
#
What memory encryption doesn't tell you
We use Trusted Execution Environment (TEE) technologies to run confidential VMs whose memory is encrypted in hardware and unreadable to the hypervisor, the host OS, and anyone administering the server. This protects data in use: the moment when data is decrypted in memory to be processed.
But memory encryption alone doesn't answer the real question; memory encryption is only the first step, and the question the introduction raised lies beyond it. A confidential VM running with the wrong kernel, a tampered boot image, or an unexpected configuration encrypts its memory just the same — and modern TEEs even protect that memory's integrity, so it can't be silently altered. Yet integrity of the memory is not the same as integrity of the workload: encryption and integrity protection tell us the operator can't read or tamper with the data in use — not whether the workload is the one we expect. That last question belongs to attestation.
A confidential VM is not automatically a trusted workload. Only once we can establish that correctly, through remote attestation, can we speak of trust at all. The TEE produces hardware-signed evidence of its state; a verifier validates the chain of trust and checks the evidence against known-good reference values; and secrets are released only if they match.
Without reference values, every correctly signed attestation report would be equally valid — including those from modified kernels or unexpected workloads. The evidence endorses a set of measurements representing the TEE state, the reference values are trusted measurements, and the policies match them to check if the TEE is in the expected state as a requirement to release the requested secret.
This makes trust explicit and verifiable by reducing it to measurable components: the hardware root of trust, the attestation evidence, the reference values used for comparison, and the policies used to attest the TEE state. No valid proof, no secrets.
#
How attestation works
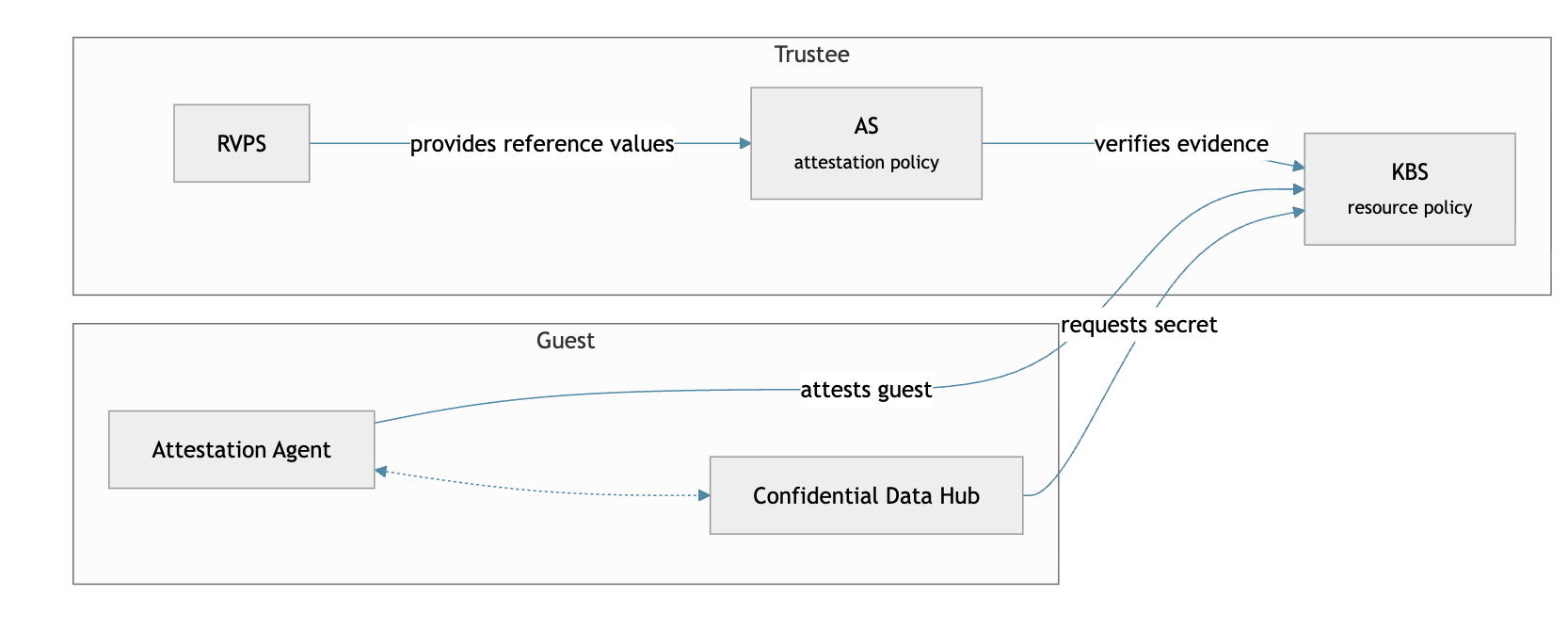
The Confidential Containers (CoCo) ecosystem we build on includes Trustee, an open-source project that bundles a set of services for attestation and secret release. That's exactly where the heart of the flow lives. The signed attestation report and its certificate chain prove that the measurements came from a genuine TEE platform, however, they are not enough to establish trust in the workload. The in-guest Attestation Agent submits its evidence to the Key Broker Service (KBS) — the entry point — which hands it to the Attestation Service (AS) for verification. The AS checks the evidence authenticity, compares the measurements against trusted reference values from the Reference Value Provider Service (RVPS), and evaluates them through attestation policy. The result returns to the KBS, which then applies its own resource policy to decide which secrets, if any, this workload may receive. The requested secret is released only if both attestation and resource policy evaluation succeed.
The components:
- Attestation Service (AS) — validates the evidence authenticity and attest it using the attestation policy
- Reference Value Provider Service (RVPS) — holds the trusted reference values that the workload's evidence is compared against, typically the known-good measurements of the TEE platform and boot.
- Key Broker Service (KBS) — the gatekeeper and entry point. Receives the evidence from the guest, drives verification, and decides which secrets this workload may access, based on its own resource policy.
- Attestation Agent (inside the VM) — gathers the evidence and submits it to the KBS.
- Confidential Data Hub (inside the VM) — fetches and unwraps the secrets once the KBS releases them.
The point of all this isn't just to verify a workload — it's to reduce the chain of trust: to shrink both who you have to trust and how many layers that trust has to pass through. Attestation pulls the host, the hypervisor, and the cluster operators out of the trusted computing base, leaving trust resting on the hardware root of trust and the evidence it signs, not on whoever runs the platform.
#
Confidential containers on OpenShift
We've seen the conceptual pieces of attestation — evidence, reference values, the verifier, the components that produce and check the proof. Now let's look at where those pieces actually sit on an OpenShift cluster.
Kata Containers moves the isolation boundary from the shared kernel to a per-pod lightweight VM with its own kernel. You keep the normal Kubernetes pod experience but gain hardware-backed isolation. kata-cc is the confidential variant: the per-pod VM is launched as a confidential VM on TEE hardware (such as AMD SEV-SNP or Intel TDX), so you get hardware-encrypted memory and an attestable boot.
On the cluster side, the OpenShift sandboxed containers operator provisions the kata-cc RuntimeClass on TEE-capable worker nodes. Opting a workload in takes a single line:
apiVersion: v1
kind: Pod
metadata:
name: myApp
annotations:
io.katacontainers.config.hypervisor.cc_init_data: <gzip+base64 of initdata.toml>
spec:
runtimeClassName: kata-ccEach pod gets its own confidential VM, while still appearing as a normal pod to the rest of the cluster. This separates administrative control from workload visibility: cluster administrators operate the platform, but trust in workload execution is established through attestation and policy, not through infrastructure ownership.
The security intent lives in initdata: an initdata.toml, gzip-compressed and base64-encoded, attached as a pod annotation. It can carry a custom Kata agent policy that overrides the guest's built-in default (governing what the guest allows the host to do), the Trustee address and its TLS certificate, and the image verification policy. The hash of initdata is bound to the attestation report and becomes part of the attested state. A cluster admin can't quietly change the policies or repoint Trustee elsewhere without breaking attestation. The policies governing guest behavior become part of the attested state, not just runtime configuration. The three things it carries — the agent policy, the image policy, and the trust anchor for Trustee — are also where the boundary stops being a diagram and starts being enforced, so it's worth looking at each in turn.
Take the kata-agent policy first. The kata-agent acts as a bridge between the host and the workload, managing container lifecycle, enforcing security policies, and monitoring processes just as a traditional container runtime would, but isolated inside a micro-VM. That API is precisely what a malicious host would reach for, so the agent policy acts as an allowlist over it: it declares which agent requests the guest will honor and refuses everything else. The call that matters most is ExecProcessRequest, the one behind kubectl exec / oc exec. Left unrestricted, it would let anyone with host access run arbitrary commands inside the confidential workload and read whatever the TEE was meant to protect — so a confidential deployment denies it, and likewise locks down the stream-reading and volume-mount calls that would otherwise hand the host a way in. Restricting this host-to-guest interface isn't optional hardening; it's what keeps the host on the outside of the boundary.
The image verification policy is the second piece, and it's where supply-chain trust enters the picture. A signed image is a cryptographic guarantee that the image hasn't been altered since it was built and signed by a trusted party — the signature is what ties the running code back to its origin. The policy itself — which signatures and signing keys count as valid — is what initdata carries; the check it describes runs inside the guest, at image-pull time. Before a workload starts inside the TEE, the in-guest runtime pulls the image and verifies its signature against that policy, and if the signature is missing or invalid the launch is aborted rather than run. Because the policy travels in initdata, its hash is already part of the attested state, so an operator can't quietly loosen the rules to admit an unsigned image without breaking attestation. And the enforcement point being inside the guest is what makes it robust: even a compromised registry doesn't help an attacker, since a substituted image won't carry the signature the policy demands and is rejected before execution. The TEE isolates the workload; the signature check is the software mechanism that guarantees it's the right workload in the first place.
The same boundary has to hold at the networking layer, and here it's easy to slip. Traffic to anything running as a confidential workload must be decrypted inside the TEE, not in front of it. On OpenShift that means the route or ingress sitting in front of the pod has to pass the encrypted connection straight through — SSL passthrough — so that TLS terminates inside the guest. If the route/ingress instead terminates TLS at the edge (or re-encrypts at that layer), the traffic is decrypted to plaintext on the untrusted worker node — outside the attested boundary — which hands anyone with access to that node a window onto exactly the data the TEE was meant to protect. With passthrough, the plaintext never exists outside the confidential VM. The rule isn't specific to any one workload: it holds for every confidential endpoint, Trustee included.
#
Policy: deciding what a proof unlocks
We've already met policy in its concrete form — the agent policy and the image policy carried in initdata. Step back from those instances and a general pattern appears: everything up to this point produces a verdict and a set of claims, and a claim on its own does nothing. What turns a claim into a decision is policy. Across the system it lives in three places — two in Trustee, and a third inside the guest.
Attestation policy lives in the Attestation Service and defines how attestation claims are evaluated and what conditions must hold for a workload to be considered trustworthy. Measurements and reference values are usually the most important inputs, but they are not the only claims a policy may evaluate. Most deployments spend more effort managing reference values than writing policy code. Policy expresses the logic; reference values define the state that logic evaluates.
Resource policy lives in the Key Broker Service and answers a different question: a workload that has been judged trustworthy — which secrets is it entitled to? The KBS acts as the policy enforcement point — once attestation succeeds, its resource policy decides which gated resources are released to that workload. In practice it's also where a deployment picks its posture — from a permissive policy that releases freely in development, to a strict, fine-grained one that gates every resource in production.
The third layer we've already seen up close: the guest policy enforced by the Kata agent inside the confidential VM — the policy controlling the host-to-guest RPC surface exposed by the agent. ExecProcessRequest (behind oc exec) is the obvious one to deny, but it isn't the only call that matters: ReadStreamRequest would let the host read a container's stdout/stderr, volume-mount calls could graft host-controlled storage into the guest, and SetPolicyRequest is the subtle one — if policy updates are permitted, a host may be able to weaken the policy before invoking otherwise restricted operations. The policy has to account for all of them. Naming it here places it alongside the other two: attestation policy decides whether the workload is trustworthy, resource policy decides what a trustworthy workload may unlock, and guest policy governs what the host may ask of the workload while it runs. Restricting that host-to-guest interface isn't optional hardening; it's part of the overall security model.
One detail ties policy back to the hardware: you can bind configuration into launch-time measured state and then evaluate the resulting attestation claims within policy. This is how a policy can insist not merely "this is a valid SEV-SNP guest," but "this is a valid SEV-SNP guest launched with exactly this configuration."
#
Who verifies the verifier?
Everything up to now has been about narrowing trust: attestation pulls the host and the hypervisor out of the picture, initdata binds the agent and image policies into the measured launch, and every secret is gated on a result that Trustee produces. We even noted that the rule to keep TLS inside the boundary applies to Trustee just as much as to the workloads. All of that funnels into one component. Trustee is what decides whether everything else is trustworthy — so the fair question is: where does Trustee run, and who protects it?
A verifier inherits the security of wherever it runs. Place it in an environment that someone can read, modify, or restart at will, and the entire chain of trust inherits that weakness — no matter how sound the attestation logic above it is. So the question isn't only how Trustee verifies workloads, but what gives Trustee itself an unshakable foundation.
For us that foundation is IBM Hyper Protect, built on IBM LinuxONE Secure Execution on s390x — a confidential computing technology that has been proven over years and already sits at the core of how we do key management. It's one of the strongest fundamentals we build on: a hardware-rooted, contract-governed environment where even the operator can't reach inside. Anchoring Trustee's root of trust there extends that same strength to the one component that most needs it. Rooting a component as critical as Trustee in Hyper Protect is what turns a chain of trust into something close to unbreakable.
The principle is simple: the component that most needs to be trusted gets the most protected home — and for us that home is IBM LinuxONE Secure Execution, the same foundation our key management already depends on.
#
The operator who tries everything
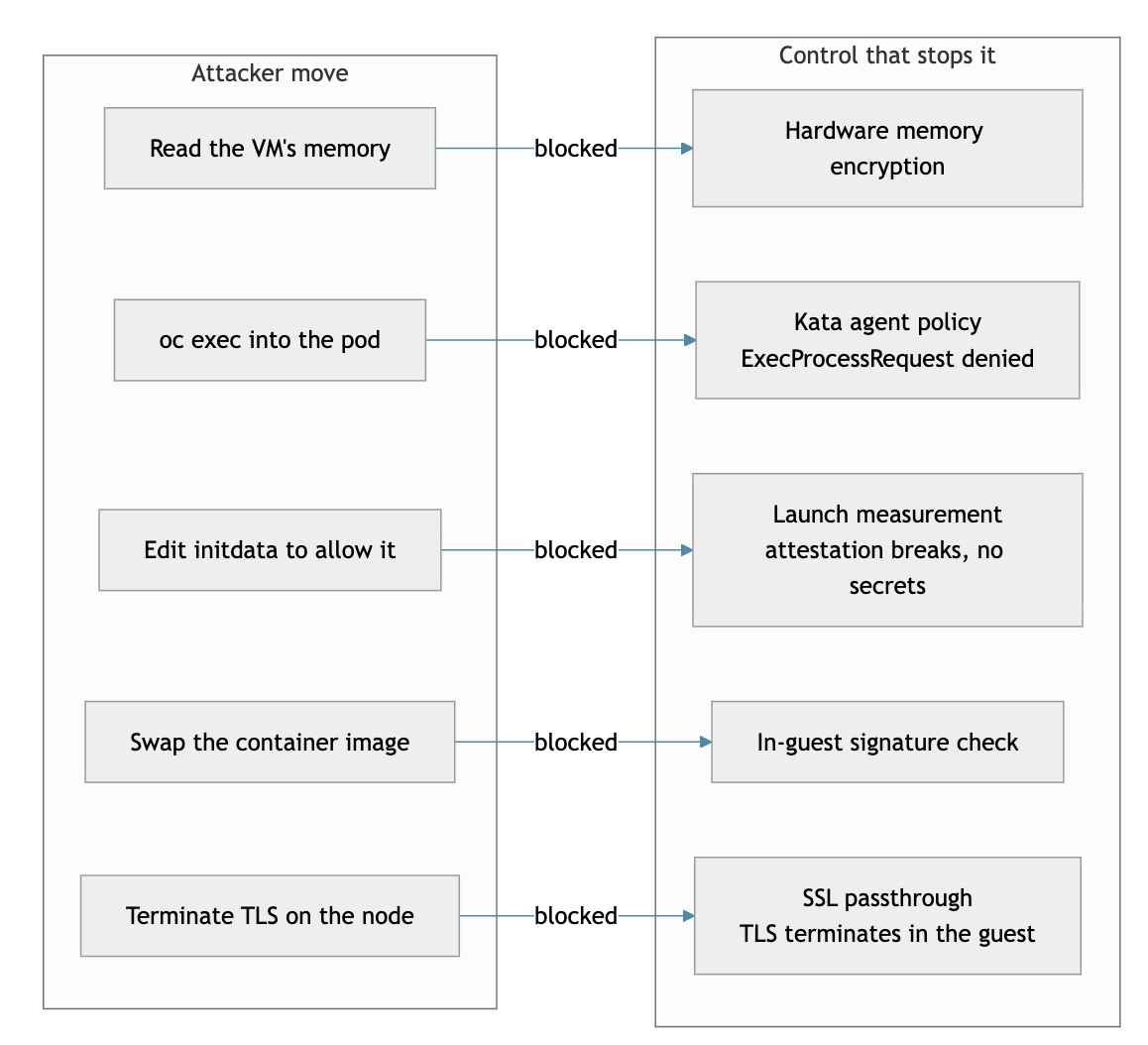
It helps to make this concrete. Picture a cluster administrator who decides to read what's inside a confidential workload — not an outside attacker, but someone with full control of the platform. Memory encryption stops them from reading the VM's RAM, so they try the host instead: oc exec into the pod. The Kata agent policy doesn't list ExecProcessRequest, so the request is refused at the guest boundary. Fine — they edit initdata to allow it. But initdata's hash is folded into the launch measurement, so the VM now attests to a different state, the reference values no longer match, and Trustee releases no secrets: the workload starts, but stays locked. They try swapping the container image for a patched one that phones memory home; the in-guest signature check rejects it before it runs. They point the route's TLS termination at the worker node to sniff plaintext; the traffic was passthrough, so there's nothing to read outside the TEE. Each move is defeated not by a different control bolted on after the fact, but by the same principle: the boundary is enforced by attestation and measured state, not by who holds admin. The one component that could undo all of this — Trustee — is the one we put out of their reach entirely.
#
Bringing it together
Since the first PoC we started with IBM Research, our central question has taken shape. A year ago the issue was whether an AI model could run inside a confidential container with the GPU inside the boundary. It can. The question now is: can you prove what's running, evaluate that proof against trusted reference values, gate every secret on the result, and put the verifier somewhere the operator can't compromise? Each section above is one half of that question answered.
Confidential computing is often reduced to encrypted memory. Memory encryption is necessary, but it's only one component of the trust model. Attestation provides the evidence. Reference values define the trusted state. Policies turn evidence into authorization decisions. Secret release becomes conditional on the result. And the verifier that makes all of this binding is itself anchored where the operator can't reach it. Only together do these mechanisms turn a confidential VM into a workload you can trust.
And this is only a slice of it. We've walked the spine of the trust model, not every vertebra: reference-value management alone is a discipline of its own once you account for CPU and GPU evidence, firmware and kernel versions, and the churn of keeping known-good values current. Workload-specific needs pull in more — encrypted storage, authenticated registries, GPU attestation, sealed secrets, application-level encryption and the key management behind it, and the operational machinery around all of it. Each of these could be its own post. What we've covered here is the load-bearing structure; the depth behind each piece is a subject we'll return to.
That's the infrastructure we're building: one where the answer to "why should I trust you with this?" is not "because we operate it responsibly," but "because you can verify it yourself."
Special thanks to IBM Research for the collaboration, Red Hat for OpenShift Sandboxed Containers, and the upstream Confidential Containers community.